How Large Language Models Work: From Data to Intelligent Conversation
Author : Ranga Technologies
Publish Date : 5 / 22 / 2026 • 3 mins read
Last Updated : 5 / 22 / 2026

Is AI Really “Thinking”, or Is It Just Predicting What Humans Want to Hear?
A few years ago, most people viewed AI as something experimental.
Today, AI writes code, explains complex topics, generates trading strategies, summarizes documents, answers technical questions, and even creates conversations that feel surprisingly human.
That shift happened incredibly fast.
Now traders, developers, students, businesses, and software engineers are all asking the same question:
1. How do Large Language Models actually work?
Because once you start using:
-
AI coding tools
-
Pine Script AI generators
-
TradingView automation systems
-
AI chat assistants
understanding what happens behind the scenes becomes important.
Especially when AI starts generating:
-
trading logic
-
financial analysis
-
Pine Script strategies
-
software code
-
automation systems
that people may eventually rely on in real environments.
Large Language Models (LLMs) are now influencing:
-
software development
-
algorithmic trading
-
content production
-
AI automation
-
search engines
-
customer support
-
strategy development
-
TradingView workflows
But despite how advanced they appear, most users still misunderstand what these systems actually do.
Some believe AI truly understands everything.
Others assume it is simply copying information from the internet.
Neither explanation is fully correct.
This article explains how LLMs process information, learn language patterns, generate responses, and why they sometimes produce inaccurate results. It also explores how Pine Script AI tools use Large Language Model technology for TradingView strategy generation, debugging, and workflow automation.
The article additionally explains why specialized AI systems like PineGen AI often perform better for Pine Script workflows compared to general-purpose AI coding tools.
2. What Is a Large Language Model?
A Large Language Model is an artificial intelligence system trained to understand and generate language patterns.
The word “large” refers to:
-
enormous datasets
-
massive computational training
-
billions of mathematical parameters
These models are trained using huge collections of:
-
books
-
websites
-
technical documentation
-
programming repositories
-
articles
-
forums
-
conversations
-
software code
The AI studies relationships between words, phrases, structures, and contexts.
Over time, it learns patterns about:
-
how humans communicate
-
how code is structured
-
how technical explanations work
-
how conversations flow
-
how questions are answered
At its core, the model predicts:
“What is the most likely next piece of text?”
But when prediction happens across billions of learned relationships, the result becomes surprisingly advanced.
This is why AI can:
-
explain software engineering
-
generate Pine Script
-
debug code
-
summarize research
-
answer questions naturally
-
build TradingView strategies
-
create long-form conversations
without truly “thinking” like humans do.
3. Why LLMs Became So Powerful
The rise of Large Language Models changed how humans interact with technology itself.
Before AI-assisted workflows:
-
coding required syntax memorization
-
automation required technical expertise
-
strategy development was slower
-
debugging consumed significant time
-
learning curves were steep
Now users can describe intentions naturally.
AI translates those intentions into:
-
software logic
-
Pine Script strategies
-
TradingView automation
-
coding structures
-
workflow explanations
That changes productivity dramatically.
For example:
A trader no longer needs to manually build every TradingView condition from scratch.
Instead, they can describe:
“Create an RSI + MACD strategy with ATR stop loss.”
Then AI generates the structure automatically.
This is why:
-
Pine Script AI
-
Pine Script generators
-
AI Pine Script generators
-
Pine Script debugger AI tools
are growing rapidly in popularity.
The value is not just automation.
The real value is:
-
iteration speed
-
reduced friction
-
faster experimentation
4. How Large Language Models Learn From Data
This is where AI becomes more technical.
LLMs do not “memorize” information like humans.
Instead, they learn statistical relationships between patterns.
4.1 Step 1 - Massive Data Training
The model is trained using enormous amounts of text and code.
This may include:
-
coding repositories
-
financial discussions
-
Pine Script examples
-
programming documentation
-
educational material
-
technical articles
During training, the AI repeatedly analyzes:
-
sentence structures
-
contextual relationships
-
coding patterns
-
conversational flow
For example:
If the model repeatedly sees:
“RSI measures momentum.”
it gradually learns:
-
what RSI refers to
-
how traders discuss momentum
-
what concepts usually connect to RSI
This happens billions of times across many domains.
4.2 Step 2 - Tokenization
AI does not process language exactly like humans.
It breaks text into smaller pieces called tokens.
For example:
“TradingView Pine Script generator”
may become several smaller computational units.
The AI then analyzes:
-
token relationships
-
sequence probabilities
-
contextual positioning
to determine what likely comes next.
4.3 Step 3 - Neural Network Optimization
The model repeatedly makes predictions during training.
When predictions are incorrect:
-
mathematical weights are adjusted
-
relationships are refined
-
probabilities improve
Over time, the AI becomes better at:
-
generating coherent text
-
understanding coding structures
-
predicting technical workflows
-
producing conversational responses
This process eventually allows AI to:
-
generate Pine Script
-
explain strategies
-
answer technical questions naturally
5. How AI Generates Human-Like Conversations
One of the biggest misconceptions about AI is that it “understands” conversations emotionally.
In reality, AI predicts conversational structure extremely effectively.
When someone asks:
“How do I create a Pine Script with AI?”
the model analyzes:
-
similar historical questions
-
coding relationships
-
TradingView workflow patterns
-
conversational structures
-
likely user intent
Then it predicts the most statistically relevant response.
This creates responses that feel intelligent because:
-
language structure is highly optimized
-
conversational flow is smooth
-
contextual prediction is advanced
However, AI still does not possess:
-
emotions
-
consciousness
-
self-awareness
-
genuine understanding
It is performing advanced language prediction at massive scale.
6. Why AI Sometimes Gives Wrong Answers
This is extremely important for traders and developers.
AI can sound highly confident while still being wrong.
That happens because Large Language Models optimize for:
-
coherent responses
-
smooth language
-
probable continuation
not guaranteed factual accuracy.
6.1 AI Hallucinations
Sometimes AI generates:
-
false information
-
incorrect code
-
invented explanations
-
inaccurate references
because it predicts likely language patterns even when certainty is weak.
This is called hallucination.
6.2 Weak Specialization
General AI tools are trained broadly across many subjects.
That means they may struggle with:
-
Pine Script execution modeling
-
TradingView-specific logic
-
multi-timeframe strategy behavior
-
risk management workflows
This is why specialized AI systems often outperform general-purpose AI in narrow domains.
6.3 Outdated Information
Some AI systems train on older datasets.
Markets evolve.
Software changes.
TradingView updates Pine Script versions.
Without specialized optimization:
- generated logic may become outdated
- workflows may break
- code may require manual correction
7. The Difference Between General AI and Specialized AI
This distinction matters a lot for traders.
General AI systems are designed to answer broad questions across many domains.
Specialized AI systems focus on one specific workflow.
That specialization changes output quality significantly.
7.1 General AI Tools
General AI tools are strong at:
-
broad conversation
-
writing assistance
-
general coding
-
summarization
But they may struggle with:
-
TradingView structure
-
Pine Script optimization
-
execution modeling
-
strategy tester compatibility
7.2 Specialized Pine Script AI Systems
Specialized Pine Script AI tools focus directly on:
-
Pine Script syntax
-
TradingView execution logic
-
debugging workflows
-
strategy generation
-
indicator structure
-
optimization workflows
This usually improves:
-
code consistency
-
strategy structure
-
iteration efficiency
-
TradingView compatibility
8. How Pine Script AI Tools Use LLM Technology
Modern Pine Script AI systems rely heavily on Large Language Models.
These tools convert natural language prompts into:
-
strategies
-
automation logic
-
Pine Script code
For example, a trader may request:
“Create a volatility breakout strategy with RSI confirmation and ATR stop loss.”
The AI then:
-
interprets trading logic
-
structures Pine Script syntax
-
builds strategy conditions
-
creates risk management logic
-
formats TradingView-compatible code
This dramatically accelerates workflow speed.
Instead of manually writing every condition, traders can focus more on:
-
optimization
-
testing
-
strategy refinement
-
market adaptation
9. Why PineGen AI Fits TradingView Workflows Better
Many traders eventually realize that generating Pine Script is only part of the process.
Real TradingView workflows also require:
-
debugging
-
iteration
-
optimization
-
structural validation
-
strategy refinement
This is where PineGen AI becomes useful.
10. PineGen AI Focuses Specifically on TradingView Workflows
Unlike broad AI tools, PineGen AI focuses directly on:
-
Pine Script generation
-
TradingView structure
-
debugging logic
-
strategy optimization
-
Pine Script refinement
This specialization reduces friction significantly.
11. PineGen AI Helps Traders Iterate Faster
Modern trading strategies rarely work perfectly on the first attempt.
Most systems require:
-
repeated testing
-
condition refinement
-
volatility adaptation
-
optimization cycles
PineGen AI helps accelerate that workflow.
Instead of spending hours:
-
fixing syntax
-
restructuring logic
-
debugging errors
traders can iterate much faster.
12. PineGen AI Supports Learning Through Iteration
Many beginners struggle because Pine Script has a learning curve.
AI-assisted workflows help users:
-
understand strategy structure
-
learn Pine Script logic faster
-
analyze generated code
-
experiment more efficiently
This improves development speed while also improving understanding over time.
13. Large Pine Script AI Example
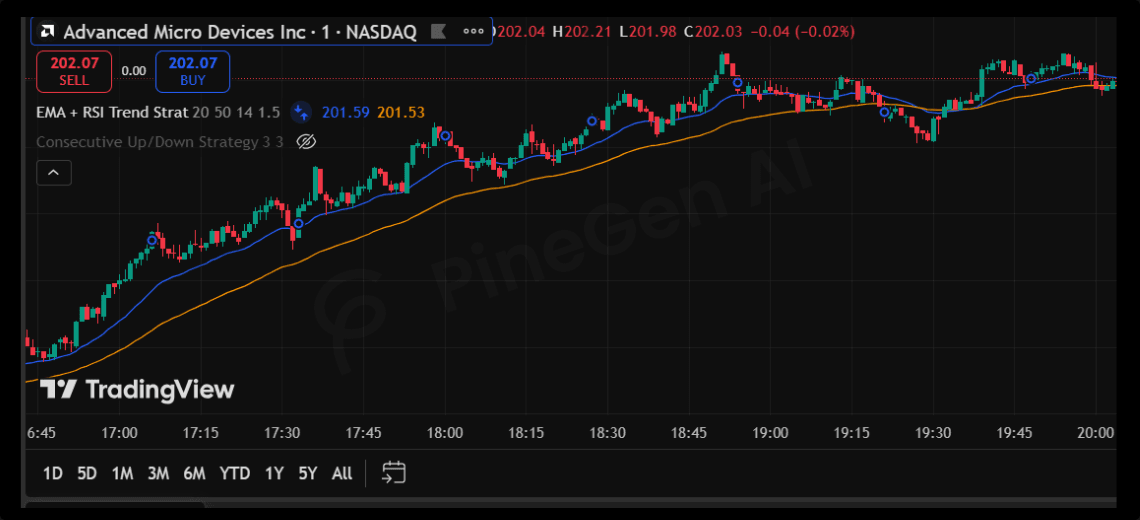
pinescript//@version=6 strategy("AI Generated Smart Momentum Strategy", overlay=true) // EMA Trend Filters fastEMA = ta.ema(close, 20) slowEMA = ta.ema(close, 50) // RSI Momentum rsiValue = ta.rsi(close, 14) // MACD [macdLine, signalLine, histLine] = ta.macd(close, 12, 26, 9) // ATR Volatility atrValue = ta.atr(14) // Volume Filter volMA = ta.sma(volume, 20) // Trend Logic bullTrend = fastEMA > slowEMA // Confirmation Logic bullRSI = rsiValue > 55 bullMACD = ta.crossover(macdLine, signalLine) strongVolume = volume > volMA // Entry Condition longCondition = bullTrend and bullRSI and bullMACD and strongVolume if longCondition strategy.entry("Long", strategy.long) // Dynamic Risk Management strategy.exit( "Exit", from_entry = "Long", stop = close - atrValue * 2, limit = close + atrValue * 3 ) // Visual Plotting plot(fastEMA) plot(slowEMA)
This type of AI-generated strategy demonstrates how LLM-powered systems can combine:
-
trend filters
-
momentum logic
-
volatility handling
-
dynamic exits
-
TradingView strategy structure
into a more advanced workflow.
14. The Real Risks of AI-Generated Systems
Despite rapid progress, AI still has major limitations.
14.1 AI Does Not Understand Risk Like Humans
AI predicts patterns.
It does not:
-
experience fear
-
understand uncertainty
-
interpret psychology
-
truly evaluate financial risk
That remains a human responsibility.
14.2 AI Can Overfit Historical Data
Some AI-generated strategies look impressive historically but fail in live markets because:
-
conditions change
-
volatility shifts
-
market behavior adapts
Testing remains critical.
14.3 AI Requires Human Validation
Even advanced Pine Script AI systems still require:
-
strategy verification
-
backtesting
-
risk review
-
logic analysis
-
optimization
AI improves workflow speed.
It does not remove responsibility.
15. How Traders Are Using AI in 2026
AI-assisted trading development is growing rapidly.
Traders increasingly use AI for:
-
Pine Script generation
-
TradingView strategy building
-
indicator creation
-
debugging
-
automation workflows
-
optimization testing
But the most successful users are not blindly trusting AI.
They are combining:
-
human market understanding
-
AI-assisted workflow speed
-
iterative optimization
-
risk management discipline
That combination is becoming far more powerful than manual workflows alone.
16. Conclusion
Large Language Models are changing how humans interact with software, coding, automation, and trading systems.
Instead of manually controlling every technical detail, users increasingly describe intentions naturally while AI converts those ideas into:
-
code
-
conversations
-
TradingView automation
-
software workflows
But understanding how these systems work matters.
LLMs are powerful because they:
-
recognize patterns at enormous scale
-
generate coherent language rapidly
-
accelerate technical workflows
-
improve iteration speed
Yet they still have limitations:
-
hallucinations
-
weak specialization
-
overconfidence
-
lack of true reasoning
For traders and developers, specialized systems like PineGen AI become especially valuable because they focus directly on:
-
Pine Script generation
-
TradingView workflows
-
debugging
-
optimization
-
strategy refinement
The future is not humans versus AI.
It is humans using AI more effectively than before.
Most traders do not fail because they lack ideas.
They fail because development becomes slow, repetitive, and difficult to scale.
Hours disappear into:
-
fixing Pine Script syntax
-
debugging TradingView errors
-
restructuring strategy logic
-
testing endless variations manually
That slows iteration.
And in trading, slow iteration usually means slower improvement.
PineGen AI helps reduce that friction.
Instead of spending most of your time manually building code, you can:
-
generate Pine Script faster
-
create TradingView strategies from natural language
-
debug logic more efficiently
-
test more strategy variations
-
optimize workflows continuously
Whether you are:
-
a beginner learning Pine Script
-
a trader building automated systems
-
a developer refining TradingView workflows
-
someone testing multiple strategy concepts daily
PineGen AI helps turn ideas into structured TradingView strategies significantly faster.
The biggest advantage is not “automatic profits.”
It is the ability to:
-
iterate faster
-
experiment more
-
refine strategies continuously
-
improve workflow efficiency over time
Because in modern trading, speed of learning matters.
Start building smarter AI-assisted TradingView strategies with PineGen AI today.